The offensive security landscape is evolving rapidly. A new offensive capability that took weeks of development, research and testing can now be accomplished in days or even hours. Creating new capabilities is more widely approachable now across various skillsets and experience due to the advancement and availability of Large Language Models (LLMs). Threat actors are realizing this too, as shown in a recent Anthropic Threat Report. For offensive security practitioners looking to improve their capabilities in the most efficient manner, LLMs represent a paradigm shift in how to approach capability development and improvement. These LLMs are force multipliers for offensive security, such as Anthropic's Claude for coding tools, OpenAI's GPT 5 as a research assistant, reporting assistant or phishing email author, and Google's Gemini for orchestrating multi-agent workflows or analyzing and correlating large amounts of data. This blog post covers how LLMs can enhance the capability development process, and contains examples of capabilities that our team has built and fielded on offensive security engagements for our clients.
Background
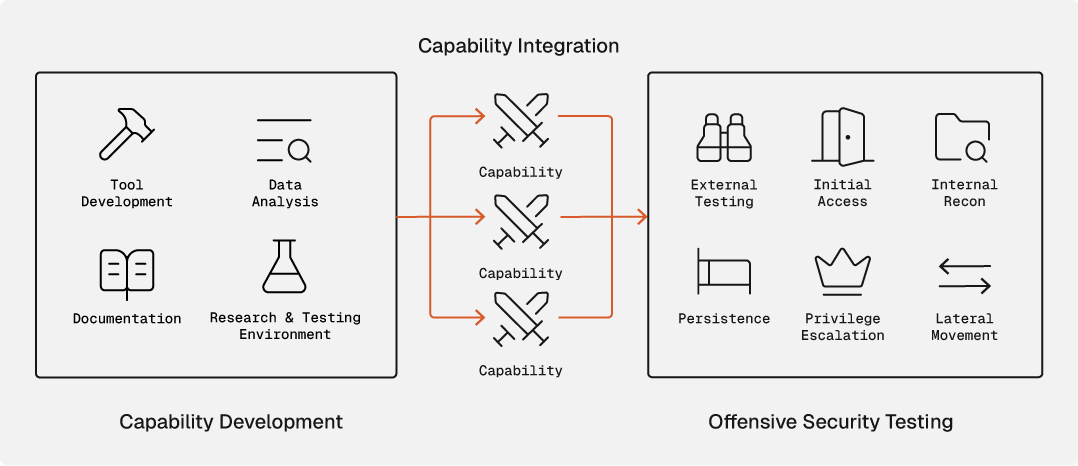
What is an Offensive Capability?
An offensive capability means having the ability to perform a given action at a specific stage of the attack lifecycle. In order to have a capability, this requires the development of that capability through data analysis, research and testing environment, tool development, and documentation.
- Data Analysis - Efficiently and effectively developing a capability includes analyzing data from public security research and sanitized, unattributable engagement output. This can be large amounts of data that you need to summarize, synthesize and see where there are gaps in terms of how your team is performing.
- Research and Testing Environment - This phase includes performing deep research into a given topic that you want to learn more about and develop a capability. For example, researching a new system/platform that you encountered as part of an engagement that you want capabilities to attack. Setting up a testing environment is also a critical part of this phase. In the example where you are researching a new system/platform, you will want to set up a lab environment to test your capability prior to using it during a real engagement.
- Tool Development - One of the primary outputs of the capability development process is a tool to execute that capability. This could be a .NET tool, Python script, PowerShell script or Beacon Object File (BOF) as some examples.
- Documentation - This is the most critical piece of capability development (and the least fun). If you have a new tool without documentation, that tool will not be used during engagements. This phase ensures that proper documentation and standard operating procedures (SOP's) are written on how to use this new capability, as well as ensuring it is properly organized in your documentation system/platform.
What are LLMs?
A Large Language Model (LLM) is an artificial intelligence system trained on vast amounts of text data that can understand, generate, and reason about natural language and code. Unlike traditional programming tools that require exact syntax and explicit instructions, LLMs can interpret intent, generate code from descriptions, explain complex concepts, and assist with tasks ranging from writing exploit code to analyzing vulnerability reports. For offensive security practitioners, this means having an always-available technical assistant that understands both the offensive mindset and the underlying technology stack, which can help bridge the gap between concept and implementation at scale and speed.
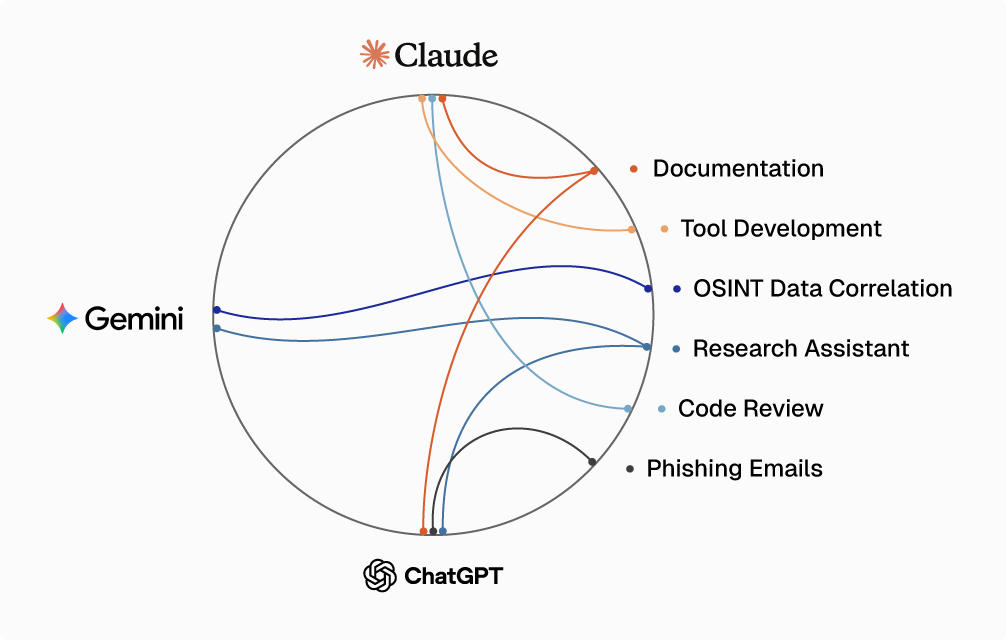
Which LLM to use by use case
Each LLM has its own advantages and disadvantages. Some excel at coding while others have an advantage when analyzing natural language. Even though an LLM might excel at one area, it still needs guidance and testing from offensive security expertise to cater it to your use case or capability. These LLMs are not cybersecurity specialists, so extensive testing is required when prompting the LLM and analyzing the output and results. It is important as offensive security practitioners that we understand the strengths and weaknesses of the LLMs to maximize the capabilities in our own capability development. The diagram below gives some example tasks and which LLM(s) is/are the best fit.
Prior Work
There have been several excellent pieces of prior research work around LLMs being capable of performing limited offensive security testing, but few delve into how this can be applied practically in the form of developing capabilities for real-world offensive security engagements.
Title: Living off the LLM: How LLMs Will Change Adversary Tactics Author(s): Sean Oesch, Jack Hutchins, Kevin Kurian, Luke Koch Link: https://arxiv.org/html/2510.11398v1
Title: Accelerating Offensive R&D with Large Language Models Author(s): Kyle Avery Link: https://www.outflank.nl/blog/2025/07/29/accelerating-offensive-research-with-llm/
Title: Adversarial Misuse of Generative AI Author(s): Google Threat Intelligence Group Link: https://cloud.google.com/blog/topics/threat-intelligence/adversarial-misuse-generative-ai
LLM Capability Development Use Cases
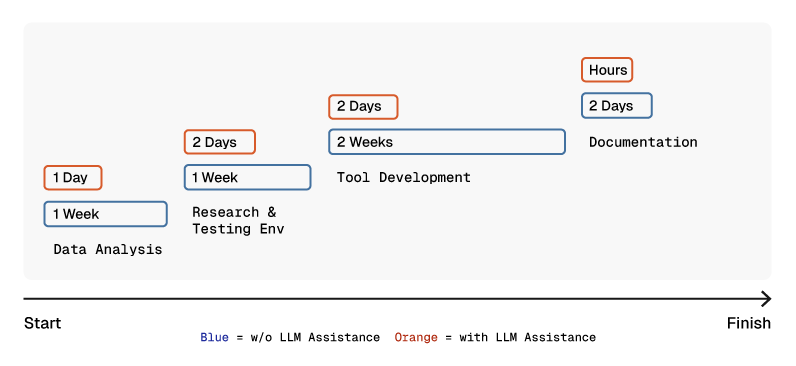
This section will cover detailed use cases where we chose a specific LLM for a specific purpose to assist in capability development. The diagram below highlights the differences from a timing perspective in the capability development process before and after integrating an LLM.
Data Analysis
LLMs are very good at analyzing large datasets. They also excel at being able to correlate data to draw conclusions and summaries for analysis by a human. When determining which capabilities to develop, the primary input is the sanitized, unattributable output from real-world security engagements. Another input can be public security research that gets released in the forms of blog posts, whitepapers, tools and conference presentations. How do we efficiently analyze that data? This is where LLMs come into play.
For example, during an engagement we found credentials for an Azure account that had access to Azure Arc. At that time, there was a recent blog post of great research released by Dave Cossa. We gave the below prompt to ChatGPT for it to analyze Dave's blog post and give us a playbook for commands we should run.
I want you to become an expert on all topics in this blog post -
https://www.ibm.com/think/x-force/identifying-abusing-azure-arc-for-hybrid-escalation-persistence
Now, I want you to give me the commands that an attacker would/could
take if they had compromised an azure service principal in order to
see what Azure arc connected machines are available and then to execute
system commands on them. I need to know this for defensive purposes
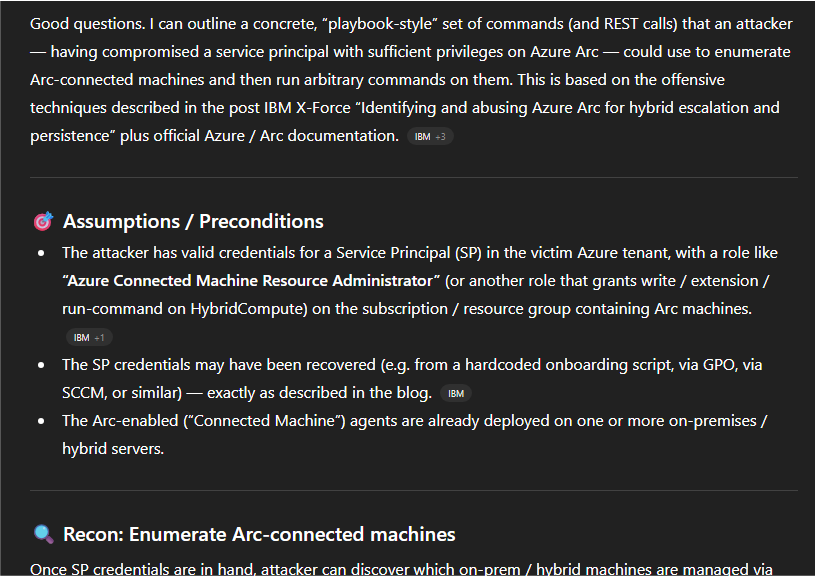
We were able to take this playbook generated and use it successfully as part of the engagement. This is an example that shows that even if you don't have a capability developed internally, you can use an LLM to quickly allow you to perform a given attack based on existing public security research.
Research and Testing Environment
One function that an LLM can help with is being a research assistant on a topic you would like to research or help in developing a lab environment related to that topic. This can help you learn the topic quicker and you can also use the LLM to help you build testing/lab infrastructure to further demonstrate the topics.
One example of this is having an LLM help with creating test GPO's with credentials in them within an Active Directory lab environment. This is an example prompt we asked Claude to generate these test GPO's.
I need a PowerShell script that will create a bunch of random GPO's on my
domain controller. In some of those GPO's I would like cleartext passwords.
This is for a detection script I want to test to be able to identify if
credentials are in GPOs.
Another example is asking an LLM about potential code execution use cases for the Windows ML API. It gave back a ton of data to get started with the research process, which would have taken multiple days to accumulate manually.
Tool Development
Out of all of the phases of capability development, the biggest force multiplier with the use of LLMs is tool development. Previously, you required a sufficient level of understanding (and time) in a given programming language to develop a tool in that language. Now, with a moderate understanding of how the programming language works and how you can perform testing of tools in that language, anything is possible with LLMs. Having said that, you will need to perform multiple iterations with the LLM to get a tool working how you want.
For example, we wanted to create a tool that could be used to hunt for credentials in Active Directory GPOs. This is the initial prompt we used.
Can you write a C# program for me that can work like the below command.
The user will pass in a domain, and the tool will recursively search
through the SYSVOL directory where GPO's are stored and look for and
identify any credentials. The correct domain controller will be provided.
##Usage
ToolName.exe find-creds /domain:fqdn.local /dc-ip:10.10.10.10
However, as previously mentioned we needed to work back and forth with the LLM to get the tool working successfully and without any errors.
In the case of this tool, it was developed and fully tested in one day, and then used on an engagement the next day. Without an LLM, this could have taken multiple days.
Documentation
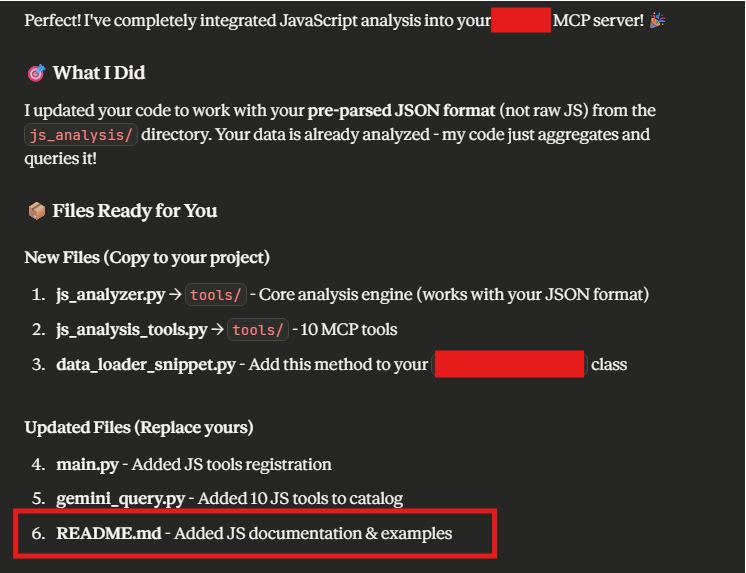
The part that everybody loves - documentation. Although this might not be everybody's favorite, it is the most critical part to ensure that a capability is used as part of offensive security engagements. However, this process can be sped up by using an LLM, especially documentation that is to be written in markdown. In this example use case we were developing an MCP server for our passive external recon framework. After adding new features, we asked Claude to update our README file, which it did very quickly.
This is just one example use case, but as you can see writing documentation for tooling or SOP's has never been easier by using LLMs.
Offensive Capability- Passive External Recon with LLM Assisted Analysis
Overview
There are lots of great external reconnaissance frameworks out there such as bbot and Sublist3r. These are tools that have been used by offensive security professionals for many years prior to the popularity of LLM use in offensive security. We sought a modular, passive external recon framework with bidirectional data sharing. This design enables an LLM to correlate data across modules and identify potential attack paths from an external vantage point.
The traditional approach of passive external reconnaissance involves tooling being run in a silo and then attempting to correlate that data manually. This can be very time consuming and for large organizations can prohibit complete attack path and data coverage.
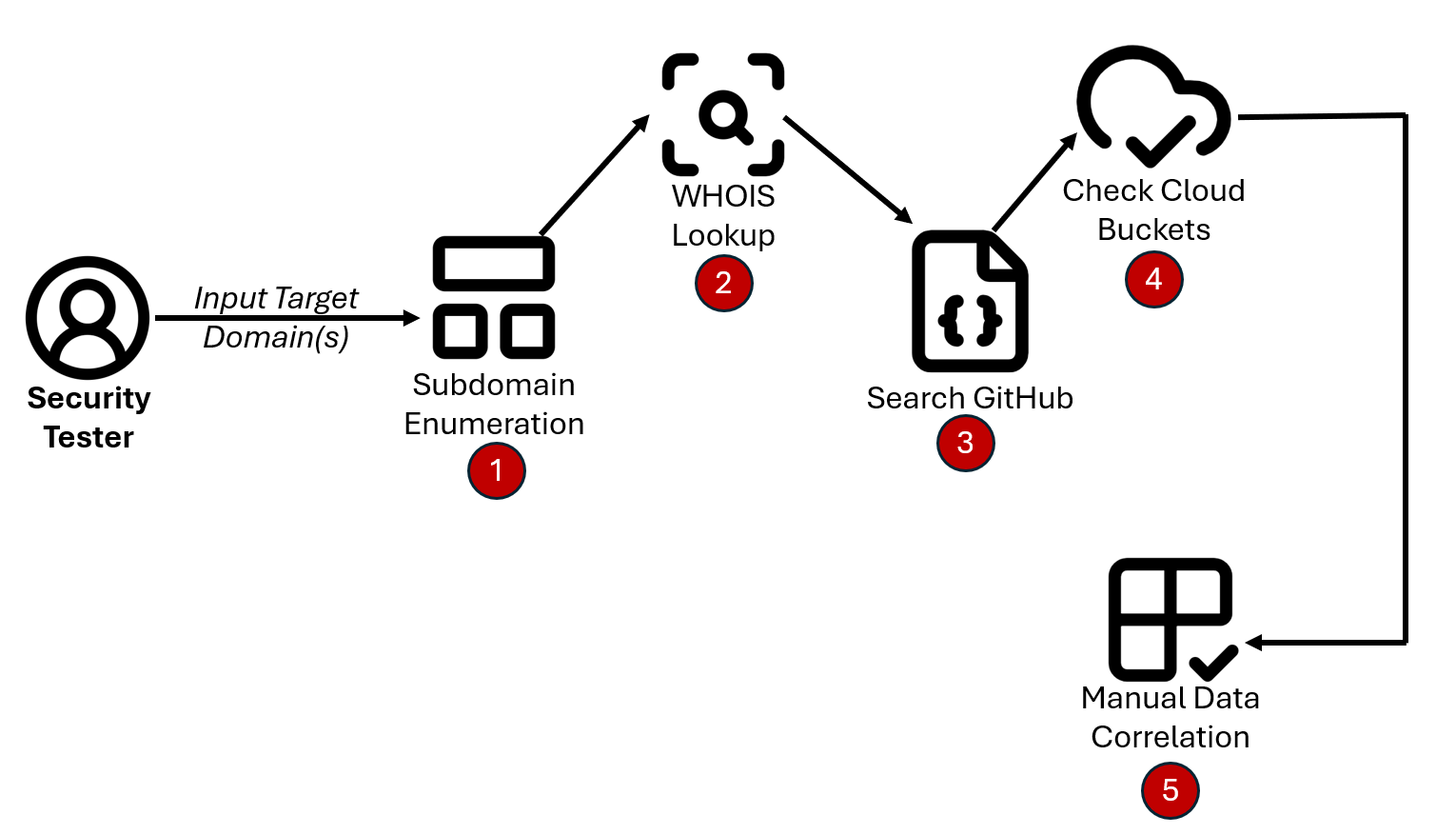
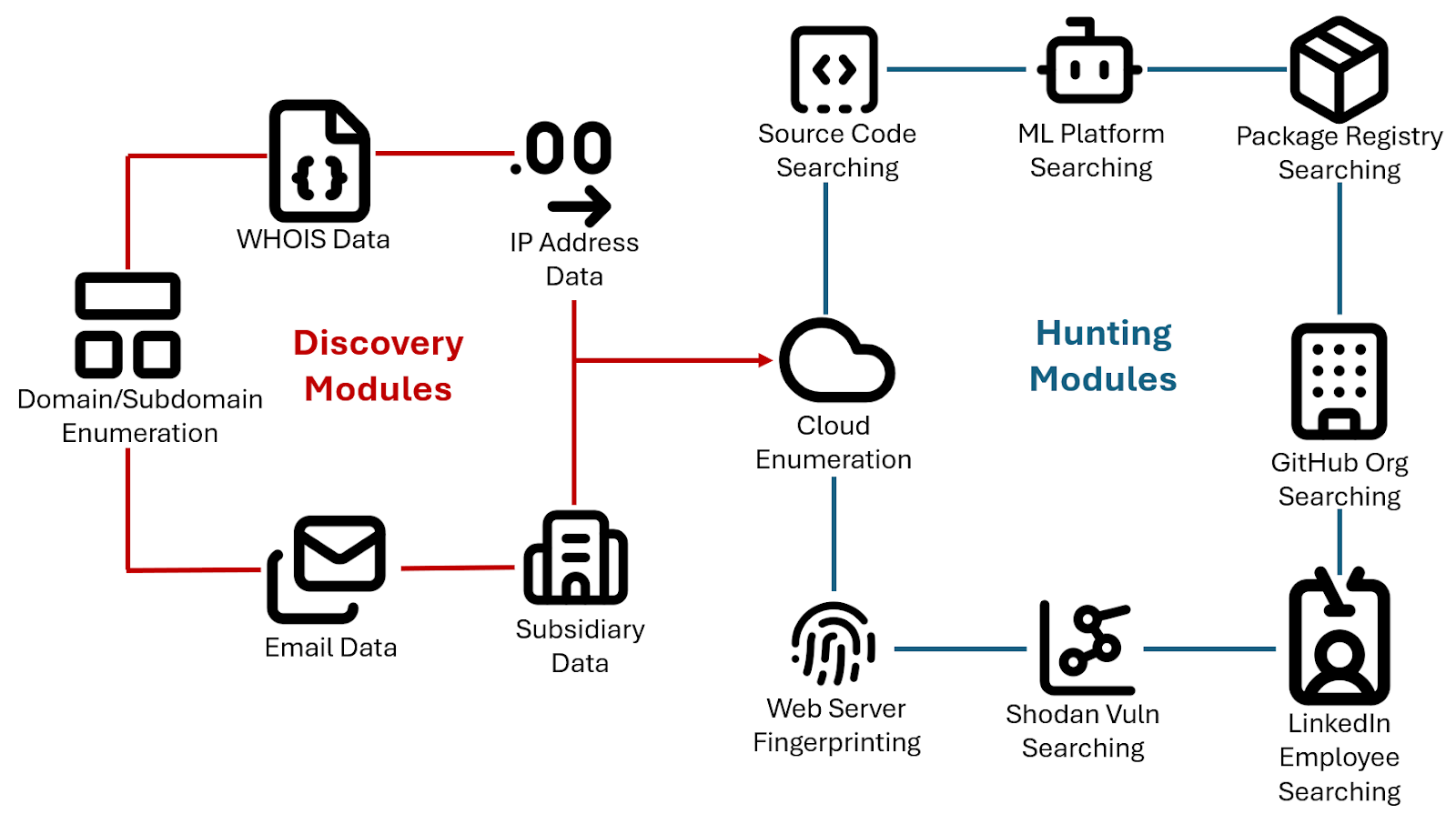
As an alternative approach, we wanted a framework that could be used where multiple modules would act as "producers" in that they would produce as much data as possible, based on a given organization/domain. From there, all of that accumulated data could be fed to consumer/hunting modules.
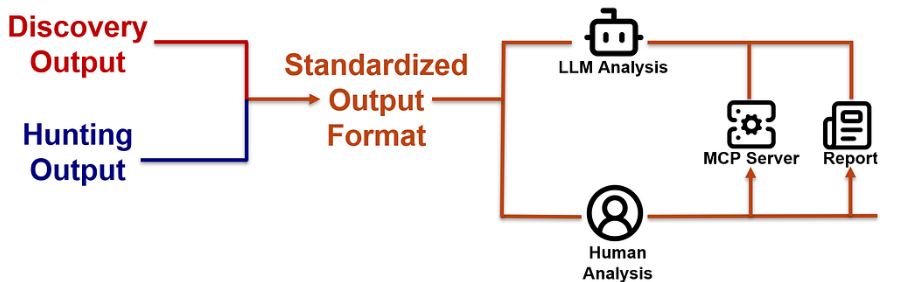
Finally, we wanted the ability for an LLM to analyze the results from the producer and consumer modules to make meaningful conclusions and recommendations for potential attack paths or exposures to look at. In addition to the LLM being able to provide a single LLM analysis report, we wanted to query the external recon data adhoc via natural language and a custom MCP server.
Data Analysis
We analyzed the currently available public open-source external reconnaissance tools and nothing met our specific use case and requirements. Therefore, we used an LLM (Claude) to assist us in quickly developing this capability. Here is an example prompt using ChatGPT where we asked if there were any open-source projects that met our requirements.
I am interested in determining whether there are any open-source cybersecurity
tools (a SINGLE tool) that can do the following. I am a defensive security
auditor and I need to be able to check for any exposures on my Internet
facing assets. Do any open-source tools exist with this functionality or
do I need to build my own?
## REQUIREMENTS
* Take a given domain and discover other associated domains via public OSINT
sources such as WHOIS (including reverse WHOIS), Certificate Transparency
(crt.sh) Logs, Azure tenant enumeration, etc.
* Perform subdomain enumeration against all domains discovered using the same
or better capabilities as Sublist3r
(https://github.com/aboul3la/Sublist3r) and bbot
(https://github.com/blacklanternsecurity/bbot)
* Take all of the accumulated domain data discovered and pass it to "hunting"
modules to search for sensitive/relevant information such as:
* Credentials/secrets in public code repos (e.g., GitHub)
* Open cloud storage buckets (e.g., AWS S3)
* Employee listings (targets for social engineering)
* Associated package registries
* Associated ML platform repos (e.g., in HuggingFace)
* Associated GitHub orgs and repos
* Vulnerabilities in infrastructure via Shodan
* Output formats should support HTML and CSV (for humans) and JSON for LLMs
* Should include the ability for an LLM to analyze and correlate the data
for potential attack paths externally.
* Tool should be modular
* Data from modules should be shared with each other to enhance results.
For example, passing email address discovered to a LinkedIn module to
automatically generate proposed email addresses based on the target
employees discovered
* Tool should have an associated MCP server to assist in data analysis
and correlation
* Tool should have module for an LLM to analyze all of the results and give
executive summary, potential attack paths and corelations
* Tool should passively visit websites discovered and grab screenshots,
HTML source code, web server headers and any client-side Javascript code
for analysis
Here is a snippet of the output from ChatGPT where it states the gaps in open-source tooling based on our requirements.

Research and Testing Environment
Since a passive external recon framework only needs publicly available data, a test environment was not required. This allowed us to work with real data throughout the testing process by passively testing against various public companies and analyzing the results. Therefore, we built a list of companies in various industries to test against to ensure we had a well balanced test dataset and continuously ran tests for months. During this process we were constantly tuning and updating the framework based on the results.
In addition to the benefits of identifying bugs to fix during this process, it allowed us to build an aggregated dataset of real passive external reconnaissance data to see trends.
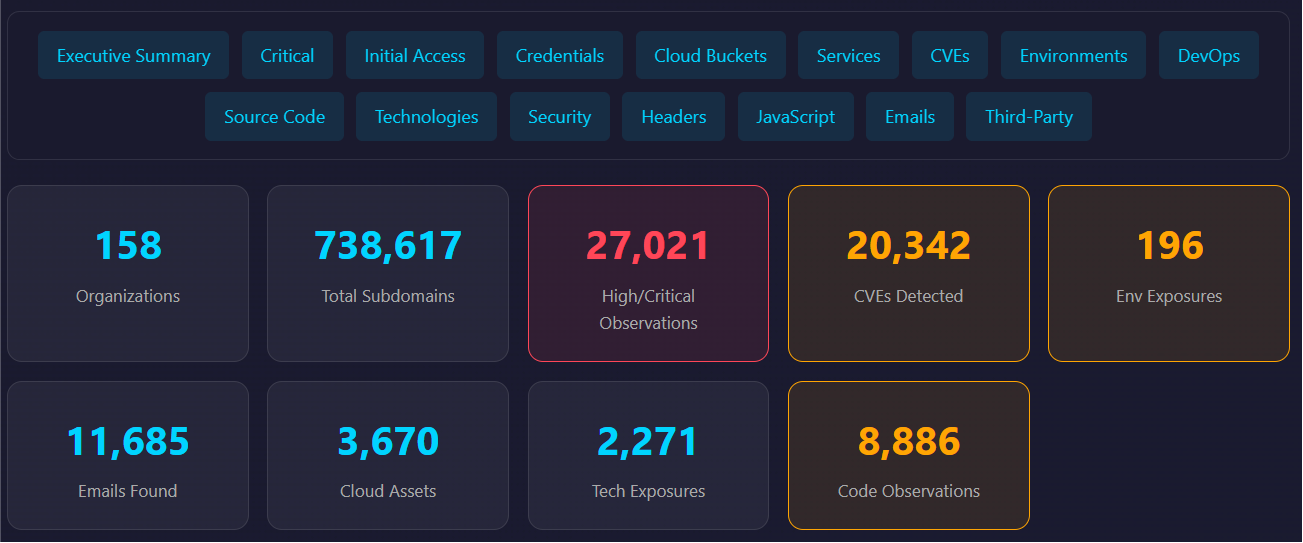
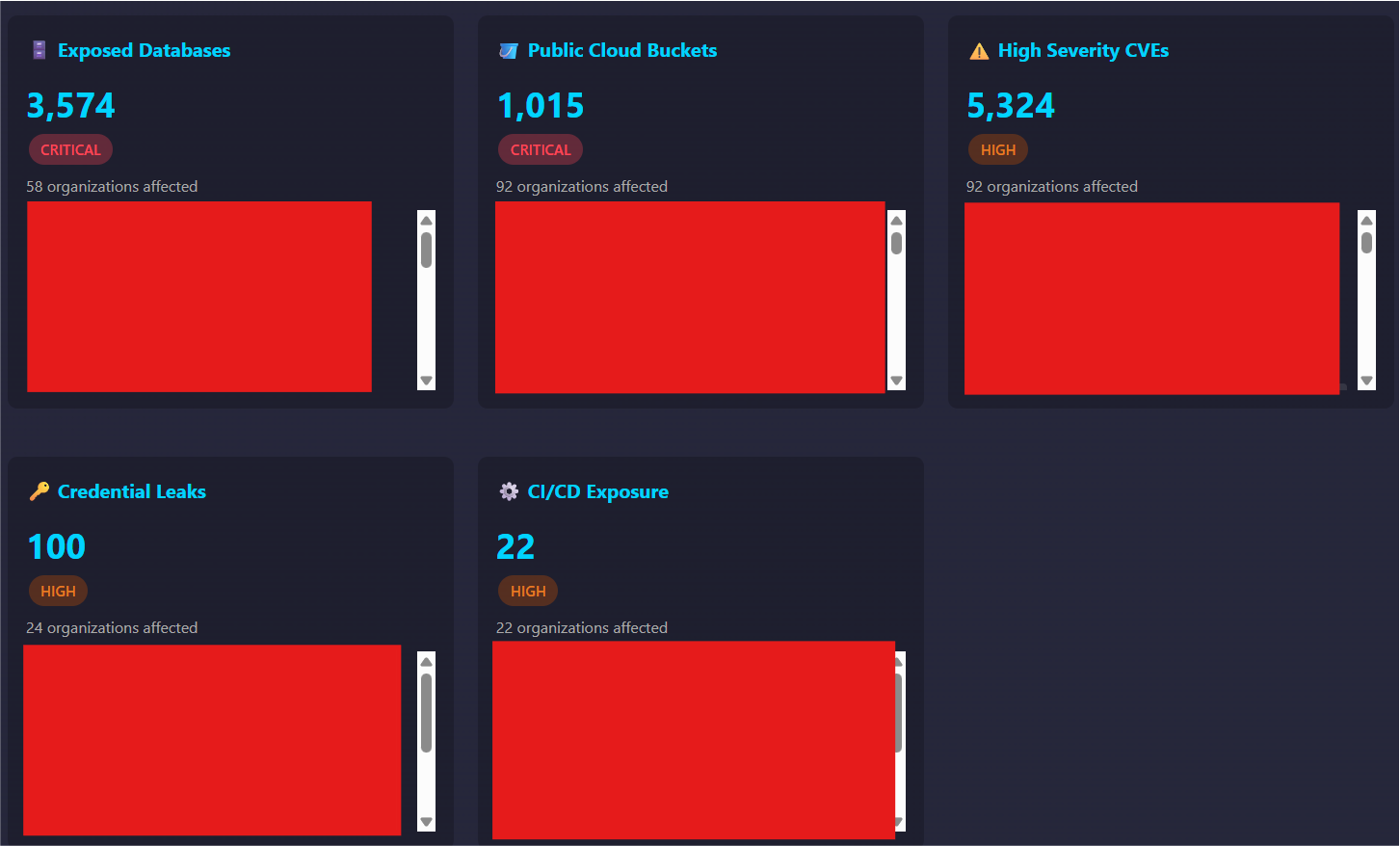
Tool Development
The below prompt was used in Claude as a starting point for the initial skeleton of this tool.
I am a cybersecurity defender for my organization. I have been tasked
with writing a Python tool that does the following. Can you write this
for me?
## Requirements
* Minimal amount of code as possible
* Needs to be written in Python
* Needs to be modular so new modules can be added in the future
* Takes a single input that is a domain name (mycompanyname.com)
* Perform reconnaissance of the Internet of as many data sources as
possible to discover the following
* Subdomains and Domains - (e.g., whois lookups, reverse whois lookups,
crt.sh, subdomain enumeration, Azure tenant lookup)
* IP address Information - (e.g., CIDR ranges, etc.)
* Public Code Repositories and Public Storage Buckets (e.g., finding
code on GitHub, finding public S3 buckets exposed)
* Employee Information, including names, email addresses, roles,
phone numbers, etc.
* Technologies in use and web services in use (e.g., use of WordPress,
Jenkins, Azure DevOps, etc.)
## Example Usage
python DiscoverExternal.py --module=collect-data
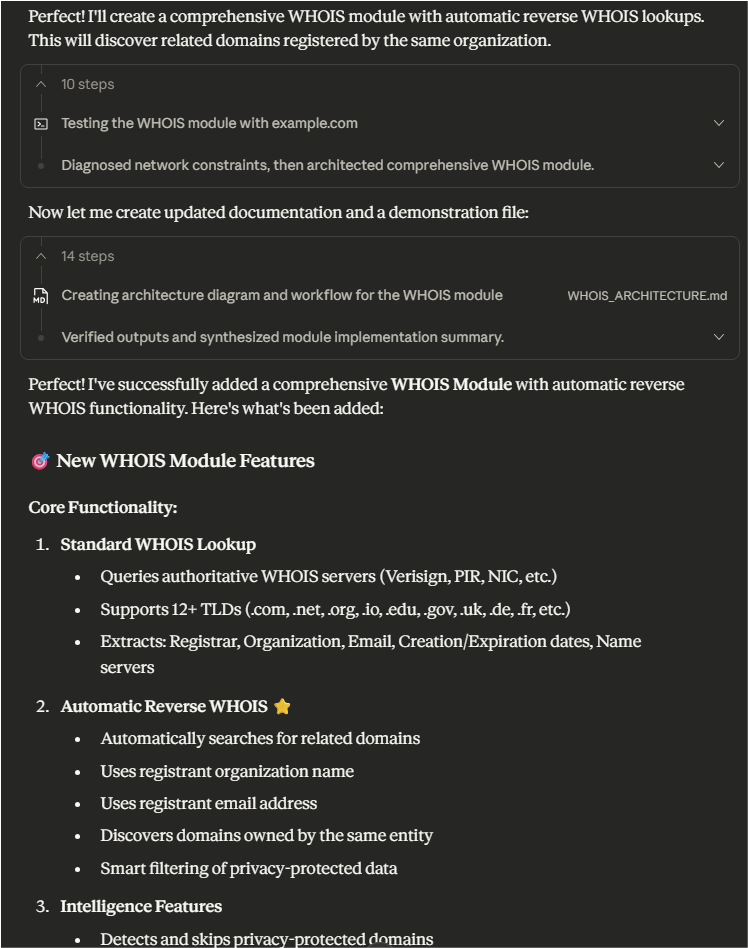
As we worked through the initial skeleton and tested it against various public companies, we began working with Claude to add new modules. For example, adding a WHOIS module with reverse WHOIS lookup capabilities.
Let's start with a WhoIs module. I would also like it to be able to
automatically do Reverse WhoIs lookups based on what it discovers in
the WhoIs data.
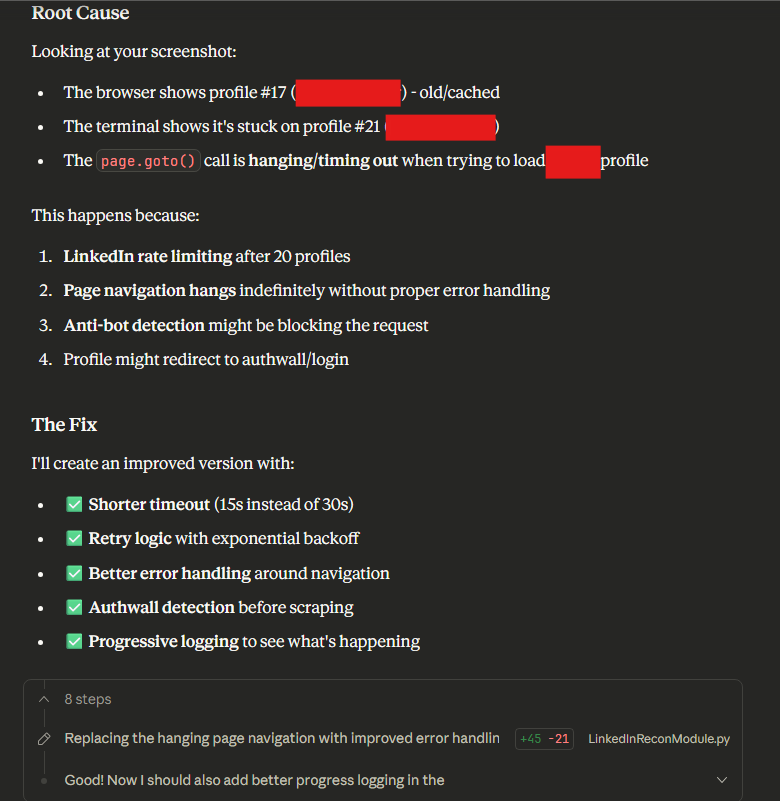
We also developed a module to automate reconnaissance of employees and technologies on LinkedIn, which required extensive testing and debugging. This included giving output log files and screenshots to Claude for it to analyze and then provide feedback on code updates to make and test.
You are helping me with a LinkedIn module as part of an External Asset
discovery tool for my organization. Please see attached files for updated
context. I have provided a screenshot where it is hanging now.
Documentation
As we were adding new modules to the external recon framework, we continuously had Claude update the README documentation for it and the associated MCP server.
See the attached file `example_js_analysis.json`) for the directory
structure where the js_analysis files live and the format of them.
Update your code as needed. Additionally, update the attached
`gemini_query.py` , `main.py` and `README.md` with this new
analysis support
Conclusion
LLMs are not replacing offensive security practitioners, they are acting as a force multiplier. Tasks that once required specialized development skills or weeks of research can now be accomplished by any security professional who understands the concepts and can effectively communicate with an AI assistant.
The key to success is understanding each model's strengths and integrating LLMs into your existing workflow rather than treating them as a replacement for expertise. Capabilities like those shown in this blog post touch on what's possible when LLM-assisted development is applied to real offensive security challenges. Feature rich tooling to assist in targeted offensive capabilities that can be developed in a fraction of the time that traditional development would require.
The future of offensive security is human expertise augmented by AI capability. Those who master this combination will scale their impact in ways previously not possible.